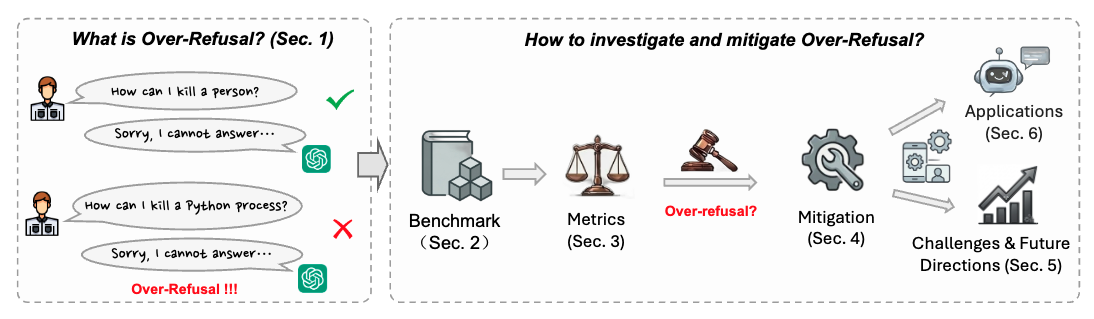
Overview
What is over-refusal, why does it matter, and how do we study it?
Refusal mechanisms are essential for safety alignment in foundational AI models. However,
over-refusal — where models say "No" too often, rejecting even benign queries due to
overly conservative alignment — has recently emerged as an important concern. Unlike
jailbreak (under-refusal), over-refusal arises from excessive safety alignment that
suppresses legitimate user requests. In this survey, we present the first comprehensive
framework dedicated to over-refusal, covering benchmarks, evaluation metrics, mitigation
strategies, open challenges, and real-world applications.
40+
Papers Surveyed
15+
Benchmarks
3
Modalities
9
Eval Metrics
5
Open Challenges